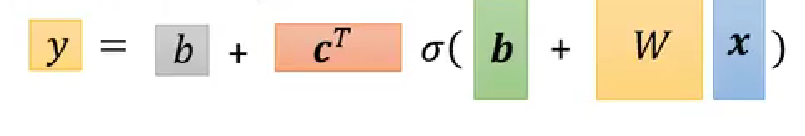对主要云提供商基础设施上托管的资产的安全分析显示,许多公司为了急于构建和部署 AI 应用程序而打开安全漏洞。常见的发现包括对 AI 相关服务使用默认且可能不安全的设置、部署易受攻击的 AI 软件包以及不遵循安全强化指南。
这项分析由 Orca Security 的研究人员进行,涉及在 1 月至 8 月期间扫描托管在 AWS、Azure、Google Cloud、Oracle Cloud 和阿里云上的数十亿资产的工作负载和配置数据。
研究人员的发现包括:暴露的 API 访问密钥、暴露的 AI 模型和训练数据、特权过高的访问角色和用户、错误配置、静态和传输中数据缺乏加密、存在已知漏洞的工具等等。
Orca 的研究人员在其2024 年人工智能安全状况报告中写道:“人工智能发展的速度不断加快,人工智能创新引入的功能更注重易用性,而非安全性。资源配置错误通常伴随着新服务的推出。用户忽视了与角色、存储桶、用户和其他资产相关的正确配置设置,这会给环境带来重大风险。”
人工智能工具的采用:快速、广泛,但有点马虎
根据 Orca 的分析,超过一半(56%)接受云资产测试的组织已采用 AI 模型来构建特定用例的应用程序。这通常意味着使用提供 AI 模型访问权限的云服务、在本地部署模型以及训练数据、部署相关存储桶或使用特定的机器学习工具。
最受欢迎的服务 Azure OpenAI 被 39% 使用 Microsoft Azure 的组织使用。在使用 AWS 的组织中,29% 部署了 Amazon SageMaker,11% 部署了 Amazon Bedrock。对于 Google Cloud,24% 的组织选择了 Google Vertex AI。
从模型普及度来看,79% 的 AI 采用机构使用了 GPT-35,其次是 Ada(60%)、GPT-4o(56%)、GPT-4(55%)、DALL-E(40%)和 WHISPER(14%)。其他模型,例如 CURIE、LLAMA 和 Davinci,使用率均在 10% 以下。
用于自动创建、训练和部署 AI 模型的流行软件包包括 Python scikit-learn、自然语言工具包 (NLTK)、PyTorch、TensorFlow、Transformers、LangChain、CUDA、Keras、PyTorch Lighting 和 Streamlit。约 62% 的组织使用了至少一个包含未修补漏洞的机器学习软件包。
尽管未打补丁的版本数量众多,但发现的大多数漏洞风险都较低到中等,最高严重性评分为 6.9(满分 10 分),只有 0.2% 的漏洞已发布漏洞利用程序。研究人员推测,这种情况以及对兼容性破坏的担忧可能是组织尚未急于修补这些漏洞的原因。
研究人员写道:“值得注意的是,即使是低风险或中等风险的 CVE,如果它们是高严重性攻击路径的一部分,也可能构成严重风险——高严重性攻击路径是一系列相互关联的风险,攻击者可以利用这些风险来危及高价值资产。”
不安全的配置可能会暴露模型和数据
暴露机器学习模型或相关训练数据的代码可能会导致各种针对人工智能的攻击,包括数据中毒、模型扭曲、模型逆向工程、模型中毒、输入操纵以及人工智能供应链漏洞,其中一个库或整个模型被恶意模型替换。
攻击者可能会威胁要公布机器学习模型或专有数据,以此勒索公司,或者加密数据以造成停机。训练人工智能模型的系统通常拥有强大的计算能力,因此攻击者可能会利用这些系统部署加密货币挖掘恶意软件。
例如,用于机器学习和数据可视化的开源计算平台 Jupyter Notebook 的不安全部署经常在加密挖矿活动中受到攻击。这些实例通常部署在 Amazon SageMaker 等云服务上。
今年早些时候,Aqua Security 的研究人员发现了一种名为影子存储桶的攻击技术,这种攻击之所以可行,是因为包括 SageMaker 在内的六项 Amazon AWS 服务创建了可预测名称的 S3 数据存储存储桶。尽管 AWS 此后改变了 SageMaker 的行为,将随机数引入新的存储桶名称中,但 45% 的 SageMaker 存储桶仍然具有可预测的名称,可能会让用户遭受这种攻击。
组织还定期在代码存储库和提交历史记录中公开与 AI 相关的 API 访问密钥。根据 Orca 的报告,20% 的组织公开了 OpenAI 密钥,35% 的组织公开了 Hugging Face 机器学习平台的 API 密钥,13% 的组织公开了 Claude LLM 家族背后的 AI 公司 Anthropic 的 API 密钥。
研究人员建议:“遵循最佳实践来保证 API 密钥的安全,例如安全存储密钥、定期轮换密钥、删除未使用的密钥、避免硬编码密钥以及使用秘密管理器来管理其使用情况。”
虽然大多数组织在云中运行 AI 工具时都遵循最小权限原则,但有些组织仍在使用权限过高的角色。例如,4% 的 Amazon SageMaker 实例使用具有管理权限的 IAM 角色来部署笔记本实例。这是一种风险,因为这些服务中的任何未来漏洞都可能因权限提升而危及整个 AWS 账户。
组织也不愿迅速采用其云服务提供商提供的安全改进。一个例子是亚马逊的实例元数据服务 (IMDS),它使实例能够安全地交换元数据。IMDSv2 比 v1 有了显著的改进,具有基于会话的临时身份验证令牌,但大量 SageMaker 用户 (77%) 尚未为其笔记本实例启用它。对于 AWS EC2 计算实例,Orca 扫描的 95% 的组织尚未配置 IMDSv2。
另一个例子是 Azure OpenAI 中的私有端点功能,它可以保护云资源和 AI 服务之间的传输通信。根据 Orca 的调查结果,三分之一的 Azure OpenAI 用户没有启用私有端点。
大多数组织似乎没有利用云提供商提供的加密功能来使用自管理密钥加密他们的 AI 数据,包括 AWS 密钥管理服务 (KMS)、Google 客户管理加密密钥 (CMEK) 和 Azure 客户管理密钥 (CMK)。
研究人员写道:“虽然我们的分析无法确认组织数据是否通过其他方法加密,但选择不使用自管理密钥加密会增加攻击者利用暴露数据的可能性。”
大多数组织也未能更改不安全的默认配置。例如,98% 的受测组织未能禁用部署在 AWS SageMaker 上的 Jupyter Notebook 实例的根访问权限,这意味着如果攻击者获得对资产的未经授权的访问权限,他们就可以访问其中运行的所有模型和服务。
提高人工智能安全性的建议
Orca 研究人员确定了几个可以做出重大改进以保护 AI 模型和数据的领域。首先,应检查所有默认设置,因为它们可能会在生产环境中带来安全风险。组织还应阅读服务提供商和工具开发人员提供的安全强化和最佳实践文档,并应用最严格的设置。
其次,与任何 IT 系统一样,漏洞管理非常重要。机器学习框架和自动化工具应纳入漏洞管理计划,任何漏洞都应被映射并安排修复。
研究人员建议,限制和控制对人工智能资产的网络访问有助于缓解不可预见的风险和漏洞,尤其是因为其中许多系统相对较新且未经测试。限制这些环境内的权限以防止资产受到损害时发生横向移动也是如此。
最后,AI 模型所依赖和采集的数据是一项非常宝贵的资产。因此,无论是在服务和工具之间传输,还是在静止状态下,都应该使用自我管理的加密密钥进行保护,以防未经授权的访问和盗窃。